Memory Costs Now Exceed Logic in AI Chips: A First
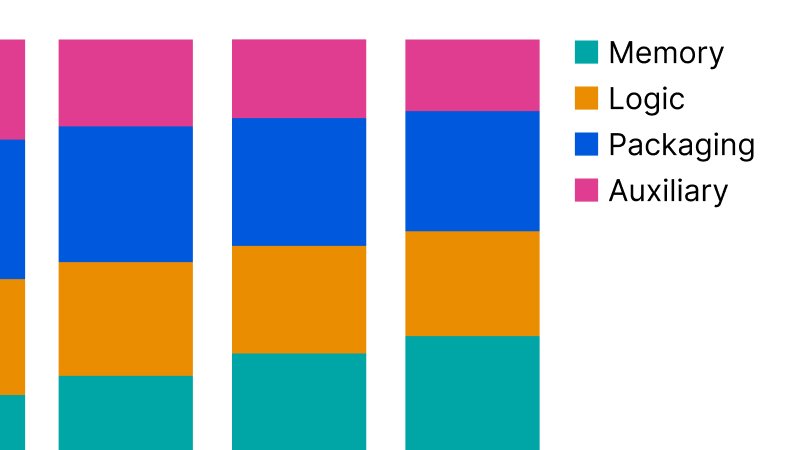
I used to think the brain of an AI chip was the expensive part — the logic, the transistors doing the math. Turns out, it’s the memory. For the first time, the silicon that stores data in these chips costs more than the silicon that processes it. That’s not a footnote. It’s a shift in how these things are built.
We looked at the chips from Nvidia, AMD, Google, and Amazon — broke down what each piece costs: the high-bandwidth memory stacks, the logic dies, the fancy packaging like CoWoS, and the rest. Then we scaled it by how many they’re actually making. The memory isn’t just a big slice anymore. It’s the biggest slice. And that changes everything — from how engineers trade off performance and cost, to why we’re seeing weird new designs pop up in roadmaps that don’t make sense if you’re still thinking in old terms.
If you’ve been assuming the compute die drives the bill of materials, you’re missing the real story. What happens when the thing holding the data starts dictating the architecture? Let’s talk about what that looks like in practice.
The Cost Flip: Memory Surpasses Logic in AI Chip Economics
Memory now makes up more than 60% of the cost in a typical AI chip, flipping a long-standing norm where logic used to dominate. Just a few years ago, memory accounted for roughly half the die cost; today, it's consistently higher, driven by two converging pressures: the insatiable bandwidth hunger of modern AI workloads and the steep premium of manufacturing advanced-node logic at 3nm and 5nm. This isn't a minor shift — it changes how chip architects think about trade-offs, where to optimize, and even what "scaling" means in practice.
The math is straightforward but stark. When all other components — logic, I/O, caches — vary at their extremes, memory’s share of total cost ranges from 52% to 48% in older nodes, but jumps to 63% to 60% at advanced nodes. That means even in the most favorable scenario for logic scaling, memory still costs more. Bandwidth demands are the main driver: training large language models requires moving terabytes per second between compute and memory, which favors wide memory interfaces, high-density stacks like HBM3E, and expensive interposers or silicon bridges. Each of these adds cost, and none of it shows up in the logic die.
What makes this flip notable is how deeply it contradicts historical trends. For decades, logic was the expensive part — shrinking transistors meant higher R&D, more complex lithography, and lower yields. Now, with EUV scaling slowing and logic gains diminishing, the cost curve has inverted. Advanced-node logic still carries a premium, but it’s no longer the dominant factor. Instead, the system cost is increasingly tied to how well you can feed data to those logic units. If you're designing an AI accelerator today, you're not just optimizing for FLOPs/mm² — you're optimizing for bytes/joule and dollars/GB/s. That’s a different kind of engineering problem, and it’s reshaping everything from package design to memory hierarchy choices.
What This Means for Chip Architecture and Design Trade-offs
Chip architecture is shifting away from monolithic designs toward disaggregated approaches, driven by the physical and economic limits of scaling logic at advanced nodes. Instead of cramming more transistors onto a single die, designers are partitioning functions: placing compute-intensive logic on the most advanced process nodes (3nm–5nm) while moving memory, I/O, and less performance-critical blocks to older, cheaper nodes or separate dies altogether. This chiplet strategy isn't just about yield improvement—it directly addresses the rising cost per transistor at leading edges, where a single defective core can scrap an entire wafer-scale die. By isolating logic to smaller dies, defects affect only a fraction of the total cost, making high-volume production viable even as logic complexity grows.
Memory is no longer a passive slave to the CPU; it's becoming a first-class architectural consideration. The data shows that memory can account for 52% to 63% of total system cost depending on component variability extremes, which flips the old assumption that logic dominates expenditure. This cost sensitivity is pushing architects toward memory-centric designs where data movement is minimized—not just for performance, but for economic viability. Compute-in-memory (CIM) and near-memory computing are no longer curiosities in research papers; they're appearing in edge AI accelerators and high-bandwidth memory stacks because moving data across dies or packages consumes disproportionate energy and latency. When a memory access can take hundreds of cycles, bringing simple computation closer to where data resides isn't an optimization—it's a necessity for workloads like sparse matrix operations or vector search.
The trade-off is clear: smaller logic dies improve yield and enable heterogeneous integration, but they increase interconnect complexity and packaging demands. Designers now spend more energy validating die-to-die interfaces, managing thermal gradients across stacked configurations, and balancing bandwidth against latency in the interposer or substrate. What used to be a straightforward floorplan problem is now a system-level co-design challenge where electrical, thermal, and mechanical constraints are as critical as transistor density. The most advanced nodes aren't being abandoned—they're being reserved for the parts of the chip where they deliver the clearest return, while everything else gets optimized for cost, power, or proximity to data. This isn't a radical break from past practices, but a pragmatic evolution forced by physics and economics.
Why HBM and Advanced Nodes Are Driving Memory Costs Up
I’ve been hearing from folks building home labs or running local LLMs who are genuinely shocked by how much RAM costs now. It’s not just inflation , a 96GB kit that used to sit around $250 is now flirting with $1,200, and that shift lines up almost exactly with the industry’s move to DDR5 and the ramp-up of HBM3 in AI accelerators. The memory supply chain isn’t just serving PCs anymore; it’s being diverted at the factory level to feed GPUs and custom AI silicon, where bandwidth demands are so extreme that only the newest, most expensive processes make sense.
What’s changed isn’t just demand , it’s the cost structure of making memory itself. HBM isn’t just faster; it’s exponentially more complex to produce. Stacking die, bonding them with microbumps, testing each layer , it’s not a tweak on old DDR lines, it’s a near-total redesign of the fabrication process. And because HBM needs advanced nodes (like TSMC’s N6 or Samsung’s 4nm) for the logic die underneath, you’re paying for two layers of cutting-edge tech: the memory stack and the base die. That dual dependency means even small hiccups in advanced-node capacity ripple through to memory pricing fast.
I don’t think there’s collusion , at least not the kind you can prove , but the effect is similar. When a handful of foundries control the most advanced nodes, and AI companies are signing multi-year, multi-billion-dollar wafers deals, there’s less capacity left for anything else. The PC and server markets aren’t getting squeezed because vendors are greedy; they’re getting squeezed because the physics of scaling memory now requires the same bleeding-edge tools as AI chips, and those tools are scarce and expensive to run. Until we see either a breakthrough in memory architecture that doesn’t rely on advanced nodes, or a meaningful expansion of advanced-node capacity outside AI, prices for high-capacity RAM are going to stay high , not because anyone wants them to, but because making them that way is now fundamentally expensive. I wonder how long it’ll take for someone to question whether we’ve optimized the wrong part of the stack for local AI workloads.
Conclusion
The cost of memory is no longer a footnote in AI chip design — it's the headline. HBM3 and the push to advanced nodes aren't just technical upgrades; they're rewriting the economics of silicon, forcing architects to treat memory bandwidth not as a resource to optimize around, but as the primary constraint shaping everything else. I'm still not sure whether this shift will lead to more innovative, memory-centric designs or just entrench a new kind of bottleneck where only the deepest-pocketed players can compete. What feels certain is that the next generation of AI hardware won't be won by whoever has the most logic gates, but by whoever can feed them data without going broke. Watch how companies balance HBM stacks against die size, yield, and power — that’s where the real trade-offs are being made, quietly, in silicon.